The Web Site Availability Model
 I am a mathematician at heart, and all mathematical conclusions are derived by deductive reasoning from a set of an initial set of assumptions (postulates or axioms). So it is natural for me to want to establish a clear foundation on which to build any discussion of performance matters.
I am a mathematician at heart, and all mathematical conclusions are derived by deductive reasoning from a set of an initial set of assumptions (postulates or axioms). So it is natural for me to want to establish a clear foundation on which to build any discussion of performance matters.To discuss matters of performance and SLM, we need to establish two kinds of frameworks: one for performance quantities (the things we must measure and manage), and another for the processes through which we conduct our measurement and management activities.
Up to now, I have been focusing largely on SLM process frameworks (like ITSO), and process details like how to select competitive response-time objectives for your site and how to report on them. Yesterday's framework dealt with how to use performance data, not with the data itself or how to collect it.
Today I am turning to the quantities that comprise performance. In my simple Web usability framework, I noted that customers have two basic needs -- Availability and Responsiveness. I am now going to expand upon those two aspects of performance, beginning today with a framework (or reference model) for thinking about site availability.
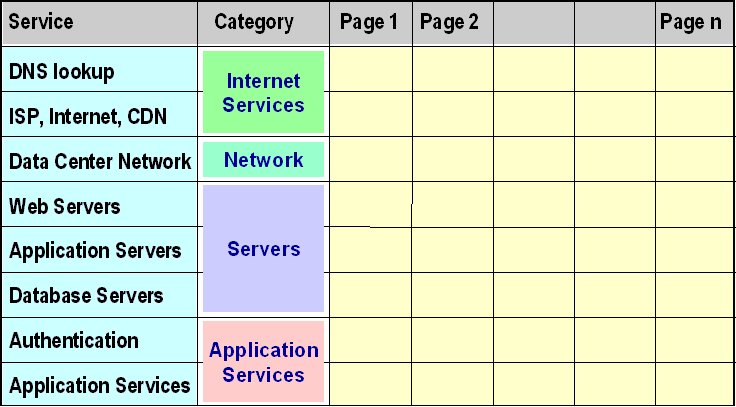
The model is illustrated by the diagram above. It is a matrix whose row and column labels are fairly self-explanatory, I think. Its cells represent common Web infrastructure components that must all work together to deliver a Web-based application to a customer. Not every page of every site will require every cell -- for example, displaying your site's home page may require only the top four cells in the first column. For more complex eBusiness applications, more of the cells will needed.
I developed this reference model in June 2005, while working on a presentation. I had previously created a similar one for response-time (E-Commerce Response Time: A Reference Model -- a topic for a forthcoming post), and I saw that my approach could also work for availability. At the time I could not find anything like it on the Web. Then last week I stumbled across an excellent paper, Application Availability:An Approach to Measurement by David M. Fishman, originally published in 2000. It includes a diagram (Figure 2. Service Decomposition) similar to the first column of mine, and the following discussion:
This is a very clear explanation of the ultimate point of an availability reference model: to deliver any service successfully to the customer, every cell that is needed must be available. So the reference model helps you understand better the diverse components that you must manage, to achieve your overall availability objectives. I will expand on this tomorrow.... a Web-based application can be decomposed into a set of measurement points for service-level indicators. A user or client of the application performing a transaction depends on all the lower-level layers to complete a transaction.
In this case, a user or client (i.e., a human or a browser) establishes a connection with a Web server over a network. The Web server connects with the application server, which processes business logic. The business logic in the application server connects to the DBMS for data retrieval as appropriate. And, of course, the DBMS runs on the operating system; it is only as available as the operating environment on which it executes.
Service availability can be measured or tracked only as a subset of the complete, end-to-end stack. With a design that allocates sufficient independence between layers, it's possible to speak of the availability of a series or set of services, each of which is a subset of the user's requirement to be up and running from end to end.
[Chris Loosley] 10/27/2005 11:29:00 PM
![]()
![]()


0 Comments:
Post a Comment