Managing Rich Internet Applications [4]
This is the fourth post in a series devoted to the challenges of Service Level Management (SLM) for Rich Internet Applications (RIAs). In these applications, some processing is transferred to the Web client while some remains on the application server. Previous posts introduced the subject, listed topics I plan to address, and reviewed RIA technologies.
The RIA Behavior Model
In an earlier post I discussed the idea of using a reference model to establish a shared frame of reference, or conceptual framework, to structure subsequent discussions of a subject. Today I introduce a new reference model -- The RIA Behavior Model -- illustrated by the diagram below.
I intend this model to represent the principal elements of the behavior of RIAs, elements that must be considered in any discussion of RIA performance and management. Note however that I am not attempting to address the complex human forces that determine perceptual, cognitive, and motor behaviors. I am merely seeking to represent a few generalized behavioral outcomes that are relevant in the context of an interaction between a human user and a Rich Internet Application.
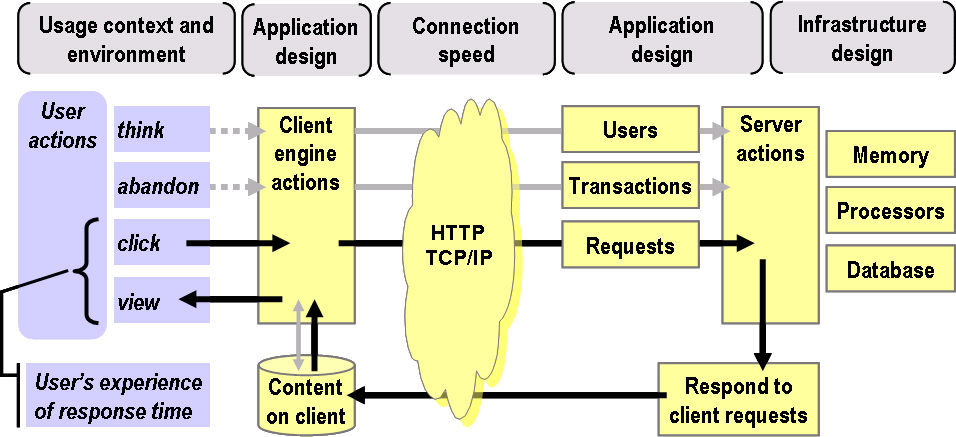
As you can see, this model embraces more concepts than the two figures created by Jesse Garrett to introduce Ajax, which I included in my previous post. Those figures are ideal for explaining the differences between traditional Web applications and RIAs. But to discuss how the combination of a Rich Internet Application and a user will actually behave, I have included several more elements that interact to determine behavior, which I will now describe.
At the highest level, the model comprises three major aspects (indicated by the color coding in the figure), each of which influences application performance:
- The application's design and usage environment, or context (upper row, grey)
- The user's expectations and behavior (lower left, blue)
- The application's behavior when used (lower right, yellow)
If we consider a Web browser to be the simplest form of client engine, then the solid black arrows trace the flow of a traditional Web page download. The user clicks on a link in their browser, the browser sends requests to one or more servers. Servers respond to client requests, and when there is enough of the requested content on the client (in the browser cache), the browser renders it ('paints' the screen), and the user can view it. The user's experience of response time is the elapsed time of the entire process, 'from click to paint'.
Even a single Web page download will normally involve many round trips between client (browser) and server, because most Web pages are an assemblage of content elements such as CSS files, script files, and embedded images, each of which is separately downloaded by the browser.
In the traditional synchronous Web application, illustrated in the upper half of Garrett's Figure 2, this process is repeated several times. Because applications usually require an exchange of information, at least one of the requests the browser sends to the server will normally be an HTTP POST (as opposed to the much more common HTTP GET request), to upload some data a user has entered into a form. Consider, for example, shopping at amazon.com as a return visitor. At minimum, even if the application recognizes you from a cookie, you must enter your password again to confirm your identity. But after that, the site already has all your personal information, and you can complete your transaction just by clicking on the right buttons on each page as it is presented to you.
Server-Side Elements
We are all familiar with this kind of Web application and its behavior. But unless you are responsible for site management or performance, you may be less aware of some of the other server-side elements of the model. Servers must field requests concurrently from many users. No matter how powerful the server, every concurrent user consumes their small share of the server's resources: memory, processor, and database.
Web servers can respond rapidly to stateless requests for information from many concurrent users, making catalog browsing a relatively fast and efficient activity. But when a user's action (such as clicking the 'add item to shopping cart' button) requires the server to update something, more of those server resources are consumed. So the number of concurrent transactions -- server interactions that update a customer's stored information -- plays a vital role in determining server performance.
In the model, the grey arrows and the boxes labeled Users and Transactions represent the fact that server performance is strongly influenced by these two concurrency factors. Servers typically perform uniformly well up to a certain concurrency level, but above that level ('the knee of the curve') transaction performance quickly degrades, as one of the underlying resources becomes a bottleneck. Because of this characteristic, seemingly small design changes in an application or in the infrastructure serving the application may, if they extend the duration of transactions, have a significant effect on the user's experience of response time.
Adding a Client-Side Engine
Adding a client-side engine does not prevent an application from implementing the traditional synchronous design described above. But RIAs aim to improve the user's experience, and a client-side engine allows the application designer to consider many additional possibilities, such as:
- Prefetching of content to client
- Lazy loading of content
- Just In Time fetching of content
- Client-side validation of user input
- Client-side only responses to user input
- Batching of server inputs on the client
- Offloading of server function to client machines
Improving the User Experience
For example, a common method of accelerating client-side response is to anticipate the user's next action(s) and program the engine to preload (or prefetch) some content 'in the background', while the user is thinking. Depending on their think time, when the user clicks, part or all of the desired response can be already available on the client. This technique has long been used in client/server systems to improve client responsiveness; a version (called Link Prefetching) is implemented by Mozilla browsers.
Preloading will certainly create a more responsive experience -- if the user actually follows the anticipated path through the application. But what if they don't? Then the client engine has made extra server requests that turned out to be unnecessary, and it still has to react to the user's input with yet more server requests. So the design has placed extra load on the servers, for no benefit.
The extra load serving these 'background' requests, on behalf of what may be hundreds or even thousands of clients running the preloading application, can slow down a server's responses to requests that users are actually waiting for. Slower responses lengthen transaction times, which drives up the number of concurrent users, clogging up the servers even more, and further slowing down responses. It's a vicious circle.
Even if the application serves some users quickly, those whose usage patterns do not match the profile the application designer had in mind will probably not receive such good service, and (in the worst case) may abandon transactions before completing them. Apart from the lost opportunity to serve a customer, abandonment usually also wastes scarce server resources, because the allocations earmarked for now-abandoned transactions languish unused until finally freed by some type of timeout mechanism.
People who design and test back-end systems already know that behavioral variables like user think-time distributions and abandonment rates per page have a significant influence on the capacity and responsiveness of servers under load. Today, RIAs (as indicated by the dotted lines in the diagram) give application designers the flexibility to create application designs that attempt to take account of such behavioral variables. But a consequence is that RIAs also magnify the risk of failure should the designer miscalculate: a simple design applied well beats a clever design misapplied.
The Application Environment
This brings us to the crucial importance of the design and usage environment, represented by the grey boxes in the model. A user's satisfaction with any application depends on their usage context and environment; in other words, how well the application design matches their needs at the time, their way of thinking, and their behavior when they are using it.
Their experience of response time depends on the combined behaviors of the client and server components of the application, which in turn depend on the application design, the underlying server infrastructure design, and of course the user's Internet connection speed. The most effective RIA will be one whose creators took into account these factors at each stage of its development life cycle, and who created the necessary management processes to ensure its success when in production.
Future Posts
Using The RIA Behavior Model as one starting point, future posts will discuss how to build robust and responsive RIAs, and explore some of the technical and management challenges they pose, especially in the area of response time measurement. If I can organize my thoughts sufficiently to keep the writer's block at bay, I expect my next post to focus on that topic.
[Chris Loosley] 3/10/2006 05:25:00 AM
![]()
![]()


0 Comments:
Post a Comment