Managing Rich Internet Applications [6]
This is the sixth post in a series devoted to the challenges of Service Level Management (SLM) for Rich Internet Applications (RIAs). In these applications, some processing is transferred to the Web client while some remains on the application server. Previous posts introduced the subject and the SLM topics I plan to address, reviewed RIA technologies, introduced The RIA Behavior Model, and introduced the application measurement topic.
Measuring RIA Responsiveness: Complications
To explain the challenges of measuring Rich Internet Applications, I will begin by reviewing three significant complications introduced by RIAs. From this discussion, I will draw conclusions about how measuring RIAs will differ from measuring traditional Web applications.
First Complication: Variety of Possible Behaviors
To make meaningful statements about an application's performance, you must first define what you need to measure. Typically you must measure common application usage patterns (or 'scenarios'), or patterns that are important by reason of their business value. When an application uses only a standard browser, its behavior is simple, known, and predictable, limiting the number of interesting usage scenarios to be measured.
Adding a client-side engine separates user interface actions from server requests and responses, giving application designers many more options. It allows developers to build an application that uses creative, clever ways to transfer display elements and portions of the processing to the client. The custom application behaviors encoded in the client-side engine make the result more complex and its usage less predictable than a traditional browser-based application. This increases the number of possible usage patterns, complicating the task of determining the important scenarios and measuring their performance.
Having many more design and implementation options also creates new opportunities for developers to make performance-related mistakes. They can (accidentally or deliberately) implement "chatty" client/server communication styles, which under some workload conditions may perform poorly. Even with thorough testing, some of these problems may remain undiscovered until after the application is deployed. A systematic SLM process must include measurement capabilities that provide a way to identify, investigate, and fix these types of problems.
Second Complication: Concurrent Activity
There are two reasons why it takes a while to download a Web page comprised of 50 separate content elements, no matter how fast your connection. First HTTP limits the rate at which clients can request objects from servers, then TCP limits the rate at which the data packets can deliver those objects from server to client. In particular, although the HTTP 1.1 standard allows clients to establish persistent connections with servers, RFC2616 defining the standard restricts the number of parallel connections the client (usually a browser) can use:
[Section 8.1.4] Clients that use persistent connections SHOULD limit the number of simultaneous connections that they maintain to a given server. A single-user client SHOULD NOT maintain more than 2 connections with any server or proxy. ... These guidelines are intended to improve HTTP response times and avoid congestion.Avoiding bottlenecks is a desirable goal in all computer systems, and so the Internet protocols are designed to protect shared network and server resources, no matter how selfishly their users might behave. But flow controls may not always be needed. Consider the metering lights that permit only two cars onto the highway every 30 seconds. During the rush hour they can smooth the flow of traffic and reduce freeway congestion, but if left on at other times, they would delay drivers for no reason. Similarly, when there is plenty of available bandwidth and no server congestion, the limit of two connections per domain is just a governor that restricts the potential rate of data transfer from server to client.
Nonetheless, modern browsers (including IE) do adhere to this guideline. And it is safest to do so, because DoS logic in some proxy servers might reject connections that do not obey the RFC2616 standard. For a lively discussion of IE behavior and the meaning of 'SHOULD' in the RFC, see this msdn blog, which also points out a relatively simple technique any Web site designer can use to circumvent this limitation, if they feel it is important enough:
Savvy web developers can take this connection limit into account and deliver their data from multiple domains, since the browser will open up to two connections per domain.Although this solution may be fast enough for many applications, most Ajax developers are looking for clever ways to make the client even more responsive. And because Ajax offers almost unlimited application design possibilities, today there is little agreement on the best ways to achieve that goal. This debate was well summarized by Jep Castelein in AJAX Latency problems: myth or reality?, a discussion that includes the important reminder that 'IE will have a maximum of 2 simultaneous connections (per domain, actually -- C.L.), whether you use XMLHttpRequest or not'. In other words, Ajax implementations are not above the law of HTTP.
Even so, a primary objective of many RIA designs is to work around the two-connection obstacle to improve responsiveness for the user. The resulting implementations will use many different techniques to communicate with one or more servers. As one data point, consider the opinion of Drew McClellan, who surely qualifies as an expert in developing Web applications. In his tutorial about JavaScript and the XMLHttpRequest object -- Very Dynamic Web Interfaces -- Drew concludes that the real challenge here is not figuring out how to make the code work but thinking of interesting ways in which it can be utilized.
Such freedom to improvise inevitably complicates measurement -- especially when requests originating from what appear to be separate units of work on a client are really all part of a single logical application. It is easy to sit on a server and measure the traffic, or the demands placed on various server-side resources. And this kind of measurement has its uses, especially when load testing or investigating bottlenecks. But the biggest challenge when measuring applications is correlating those seemingly separate pieces of information with a particular application activity, task, or phase. The more complex the client/server relationship, especially when it involves concurrent interactions, the trickier it becomes for measurement and analysis tools to perform that correlation properly.
Third Complication: Asynchronous and Synchronous Communications
An earlier post discussed RIA technologies. It described how Flash and Ajax use client-side engines that can be programmed to communicate asynchronously with server(s), independent of a user's actions. This notion is captured in name 'Ajax', in which the initial 'A' stands for 'Asynchronous', and Figure 2 in that post was taken from Jesse James Garrett's seminal article on Ajax. Although Garrett's figure does show how an engine enables asynchronous application behaviors, and differs from a traditional Web app, it does not illustrate the full range of possibilities, which I discussed further in RIA post #4. In general, a user action within a Rich Internet Application can trigger zero, one, or many server requests.
 Also, most discussions of RIA architecture or technology focus on how asynchronous application behaviors can improve usability. But they don't question the fact that communication between browser and server is still synchronous. That is, communication is always initiated by the browser (or the client-side engine operating as an extension of the browser), and follows the standard synchronous HTTP request and response protocol. But in a recent blog post and presentation, Alex Russell of dojo proposed the name Comet for a collection of clever techniques that exploit HTTP persistent connections to implement a 'push' model of communication.
Also, most discussions of RIA architecture or technology focus on how asynchronous application behaviors can improve usability. But they don't question the fact that communication between browser and server is still synchronous. That is, communication is always initiated by the browser (or the client-side engine operating as an extension of the browser), and follows the standard synchronous HTTP request and response protocol. But in a recent blog post and presentation, Alex Russell of dojo proposed the name Comet for a collection of clever techniques that exploit HTTP persistent connections to implement a 'push' model of communication. He used an adaptation of Garrett's original Ajax figure to show how Comet extends the Ajax model; this smaller version comes from brainblog:

Using the Comet techniques, a server uses long-lived persistent connections to send updates to many clients, without even receiving a request (a 'poll') from the client. According to Russell:
As is illustrated above, Comet applications can deliver data to the client at any time, not only in response to user input. The data is delivered over a single, previously-opened connection. This approach reduces the latency for data delivery significantly.Like Ajax, Comet is not a new technology, but a new name for some clever ways to implement an old communication style using standard Web protocols. But as happened with Ajax in 2005, the new name has triggered a lot of interest among developers -- for evidence, just search on 'Ajax', 'Comet', and 'Web' (the last term should eliminate most links to Greek legends, soccer legends, and legendary cleaning products). Especially useful are Russell's slides from his talk (Comet: Low Latency Data For Browsers) at the recent O'Reilly ETech Conference, and Phil Windley's excellent write-up of the talk.
The architecture relies on a view of data which is event driven on both sides of the HTTP connection. Engineers familiar with SOA or message oriented middleware will find this diagram to be amazingly familiar. The only substantive change is that the endpoint is the browser.
While Comet is similar to Ajax in that it's asynchronous, applications that implement the Comet style can communicate state changes with almost negligible latency. This makes it suitable for many types of monitoring and multi-user collaboration applications which would otherwise be difficult or impossible to handle in a browser without plugins.
The complexity of a push architecture is justified only for applications that manage highly volatile shared data. But when it is implemented, it creates an entirely new set of measurement challenges. If information pushed to the client does help the user to work faster, its benefits will be reflected in normal measurements of application responsiveness. But you can't use normal responsiveness metrics to evaluate a server-initiated activity that simply updates information a user is already working with.
New metrics must be devised. Depending on the application, we may need to measure the currency or staleness of information available to the user, or maybe the percentage of times a user's action is invalidated by a newly received context update from the server. This kind of "hiccup" metric is conceptually similar to the frequency of rebuffering incidents, one measure of streaming quality. Server capacity will also be a major issue requiring careful design and load testing. These are new SLM challenges facing anyone who decides to implement the Comet approach.
Measuring RIA Responsiveness: Conclusions
While discussing the three major complications introduced by RIAs, I have already noted some consequences: measurements may become harder to specify, more difficult to correlate, and may even require the invention of new metrics. But I have been saving the punch-line until the end. I will now discuss my three most important and far-reaching conclusions about measuring RIAs, each of which involves a significant change from the way Web applications are measured today. These changes deal with the issues of what, where, and how to measure.
RIAs: What to Measure?
The short answer? Not individual Web pages. First and foremost, because the asynchronous aspects of the RIA model undermine two fundamental assumptions about Web applications and what to measure:
- We can no longer think of a Web application as comprising a series of Web pages.
- We can no longer assume that the time it takes to complete a Web page download corresponds to something a user perceives as important.
Therefore to report useful measurements of the user experience of response times, instead of relying on the definition of physical Web pages to drive the subdivision of application response times, we must break the application into what we might call 'logical pages'. To do this, a measurement tool must recognize meaningful application milestones or markers that signal logical boundaries of interest for reporting, and thus subdivide the application so that we can identify and report response times by logical page.
Because (as I noted earlier) it is usually hard to correlate seemingly separate pieces of measurement data after the fact, I conclude that these milestones will have to be identified before measurement takes place. They could be key events or downloads that always occur naturally within the application. Or they could require proactive instrumentation, for example using little downloadable content elements that developers deliberately imbed at logical boundaries in the application's flow, to enable its subsequent measurement.
The former method places the burden on those setting up measurements to first identify application-specific milestones. The latter frees the measurement tool from the need to know anything about the application, but places the burden on application developers to instrument their code by inserting markers at key points.
Comparing Apples and Oranges?
Second, when setting out to measure a RIA, you must think carefully about the purpose of the measurement, especially if the RIA is replacing a traditional Web application, or being compared with one. You must not let the traditional Web approach to a business task determine what measurements are taken. Aleks Šušnjar (see post [2] in this series) provided the following insights:
We can't compare apples and oranges by measuring either an apple or an orange. We need to approach measurement as if we were comparing two applications built by different developers -- one a traditional Webapp and the other a client/server app with a completely different UI.Aleks' insights come from his own experience developing a Rich Internet Application -- for more details see his Wikipedia page about RIA and AJAX.
In this situation, we cannot measure only at the level of single Web pages or server interactions. Finding that it takes so many milliseconds to get a server response for request-type X is meaningless if that client/server interaction does not occur in both versions of the application.
In my experience, a typical example concerned how long it took to upload or download a document. But those metrics were sometimes irrelevant, depending on the application context. So to make really useful performance comparisons, we had to approach the problem at a higher level -- for example, 'how long does it take to move a document from folder A to folder B?' In a traditional Web app that task would likely require multiple clicks on separate pages, whereas with an RIA/Ajax implementation, we could do it with a single drag and drop.
So to make valid comparisons, we had to measure and compare the net effect of two rather different aspects of performance -- one concerning only the computer (how many operations of type X can a machine perform per hour), the other involving human performance (how many documents can an employee move per hour). But both affected the overall conclusion. Generalizing, I would say that:In the final analysis, all these components of application performance must be weighed.
- The server that has to generate additional HTML for multiple responses in a traditional Web app will likely use many more processor cycles than the one supporting an RIA/Ajax implementation, where all the user interactions are handled on the client and the server just has to provide a service at the end.
- If the designer takes care to avoid 'chatty' client/server communications, network utilization will probably also be significantly lower in the second case, further improving server performance.
- Finally, if the client-side interface is well designed, a RIA should allow users to think and work faster.
RIAs: Where to Measure?
You might think that to measure a user's experience of responsiveness, you would have to use a tool that collects measurements from the user's workstation, or at least from a measurement computer that is programmed to generate synthetic actions that imitate the behavior of a typical user. Surprisingly, this is not actually the case for traditional Web applications.
While synthetic measurements require computers to mimic both a user's actions and their geographical location, software that collects passive measurements of real user actions can in fact reside either on the client machine or on a machine that is close to the server, usually just behind the firewall -- just so long as that machine can observe the flow of network traffic at the TCP and HTTP levels. Because of the synchronous and predictable nature of these protocols, a measurement tool that can read and interpret the flow of packets can actually deduce the user's experience of response time by tracking HTTP message traffic and the lower-level timings of TCP data packets and (crucially) TCP acknowledgements.
Such a tool is called a packet sniffer, or protocol analyzer. Packet sniffing has a bad name in some quarters, being associated with malicious snooping by hackers. But in the right hands, it is a legitimate analysis technique used by some Web measurement tools to deduce client-side performance without actually installing any components, hardware or software, anywhere near the users.
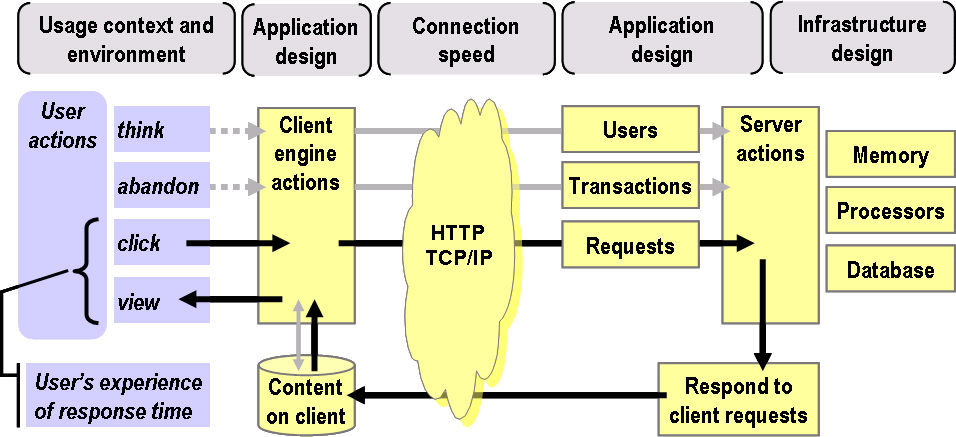
Unfortunately for these tools, the growth of RIAs will make it progressively more difficult to exploit this clever approach. The RIA Behavior Reference Model (this figure) I introduced previously makes it clear that RIAs -- even without the further complications introduced by a Comet push architecture severely limit the power of the packet sniffing approach. That's because we can no longer characterize response time as the time to complete the synchronous round trip of:
Click(C) => Browser(B) => Request(Q) => Server(S) => Response(R) => Display(D)
Instead the client-side engine in the RIA architecture breaks apart this cycle into two separate cycles operating asynchronously:
The user-client cycle: Click(C) => Engine(E) => Display(D) -- [CED, for short]
The client-server cycle: Request(Q) => Server(S) => Response(R) -- [QSR, for short]
Another way of describing these cycles might be as 'foreground' (CED) and 'background' (QSR). Both cycles are important, because neither stands alone; it is their relationship that defines application behavior. But that relationship depends only on the application design, which cannot (in general) be inferred by a measurement tool, especially one that can observe only one of the two cycles.
I conclude therefore that to measure RIAs, tools will have to reside on the client machine, where they can see both the level of responsiveness experienced by the browser (the QSR cycle) and the user's experience of responsiveness (the CED cycle). Granted, QSR cycles can still be monitored by the traditional packet sniffing methods, but tracking them will permit only limited inferences to be made about the CED cycle, which is separately managed by the client-side engine.
One might imagine that tracking the times of certain previously identified 'marker' objects within the QSR stream could solve this problem, especially since I already concluded (above) that marker objects will be needed to delimit the logical pages of RIAs. But in order to be able to draw conclusions about CED times by seeing those markers in the QSR stream, a measurement tool must impose a lot of constraints on the design of the client-side engine. An engine that implemented truly asynchronous behaviors (such as anticipatory buffering) would make it difficult or impossible to assess the user's actual experience without a measurement presence on the client side to observe the CED cycle.
Either that, or the marker objects would themselves need to be active scripts that triggered timing events that were somehow transmitted to the server (in a manner similar to ARM), rather than simply being passive milestones. But once again, this approach is tantamount to placing a measurement capability on the client. (Indeed, in the context of RIAs, dynamically distributing little measurement scripts that function as extensions to the client-side engine would be a natural approach). I therefore conclude that an approach comprising only passive listening on the server side will be insufficient to measure RIA responsiveness.
RIAs: How to Measure?
We have seen that RIAs will affect where a passive measurement tool can be used. Active measurement tools, because their modus operandi is to simulate the user's behavior, are not affected by this issue -- since they mimic the client, they naturally reside there. For these measurement tools, the issue raised by RIAs is how closely a user's behavior needs to be emulated.
User Actions: First, note that RIAs can generate back-end traffic in response to any user action, and not only when the user clicks. For example, the Google maps application can trigger preloading of adjacent map segments based on the direction of a user's cursor movement within the map display. Therefore to measure RIA responsiveness, an active measurement tool must simulate the user's actions, not the engine's actions. This further explains why active tools must reside at the client.
In other words, using the terminology introduced earlier, active measurement tools must drive the CED cycle, not the QSR cycle. The former involves driving the client-side engine to obtain its backend behavior; the latter would require the tool user to supply a complete script of the engine's behavior to the active measurement tool. The latter involves more work and is inherently more difficult and mistake prone, and therefore much less useful.
Think Times: Second, an active measurement tool must properly reflect then fact that a client-side engine may be doing useful work in the background, while a user is reading the previous response or deciding what to do next. It may, for example, be prefetching content in anticipation of the user's next action. Therefore the time a user devotes to these activities -- jointly represented as 'think time' in the RIA Behavior Model -- may affect their perception of the application's responsiveness.
For passive measurements of real user traffic, this is not a problem, because their measurement data always includes the effects of the users' actual think times. But for traditional Web apps, synthetic measurement tools have not needed to simulate think times by pausing between simulated actions, because introducing such delays would not have altered the result. When measuring an RIA however, setting think time to zero (as is typically done today) could have the effect of eliminating or minimizing potential background preloading activity, thus maximizing the perceived response times of later user actions.
And because the engine's behavior during think time varies by application, a measurement tool cannot simply measure content download times then introduce simulated think times during the reporting phase. Combining individual component measurements after the fact to produce a realistic estimate of user experience would be like trying to construct a PERT chart for a volatile project when you are not sure you know all the tasks and also cannot be sure about all their interdependencies -- in other words, impossible.
While people familiar with the project could probably construct the chart and draw conclusions about the project's duration, a general-purpose tool cannot. But in software performance and analysis work, the most difficult and error-prone aspect is combining low level measurements to draw conclusions about user-related metrics like transaction response time. So most users of application measurement tools want to be told the bottom line, namely the user experience, not just the underlying component times.
Therefore I conclude that to reflect a user's experience, an active measurement tool will have to simulate user think times during the measurement process. Using realistic think times (as the best load testing tools already do today) will produce the most realistic measure of the response times a user perceives during a particular application use case.
Summary
Since this has been a long post I will now summarize my conclusions, with links back to the discussion behind each:
- The variety of possible RIA behaviors creates new opportunities for developers to make performance-related mistakes, requiring more systematic approaches to measurement.
- Concurrent client/server interactions make it difficult for measurement and analysis tools to correlate seemingly separate pieces of data with a particular application activity.
- RIA push models (like 'Comet') will require the invention of new metrics to measure effectiveness.
- Milestones must be specified in advance to allow measurement tools to group RIA measurements into 'logical pages' or tasks.
- To compare the performance of a RIA with a traditional Webapp, you must measure equally important activities within each.
- Passive monitoring of server requests will be insufficient to determine a user's perception of RIA responsiveness.
- Active measurement tools must simulate user actions, not just engine actions, to measure RIA responsiveness.
- Active measurement tools must simulate user think times during the measurement process, to reflect a user's experience accurately.
This completes (for now) my analysis of the challenges of measuring RIAs; any further ideas will have to wait until future posts. Next I will consider how the introduction of RIAs may affect SLM processes that were designed and fine-tuned to manage traditional Web applications.
[Chris Loosley] 3/25/2006 07:14:00 PM
![]()
![]()


{kind=link}
0 Comments:
Post a Comment