The Value of Reference Models
A reference model establishes a shared foundation -- a frame of reference, or conceptual framework -- that can then be used to structure subsequent discussions of a subject. For more details, the best resource I could locate online is this discussion of the OASIS SOA Reference Model. Its focus is different from ours, but it contains some good general points, including:
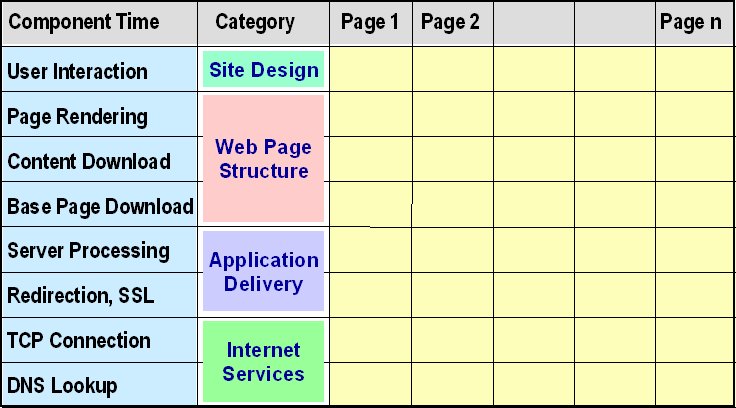
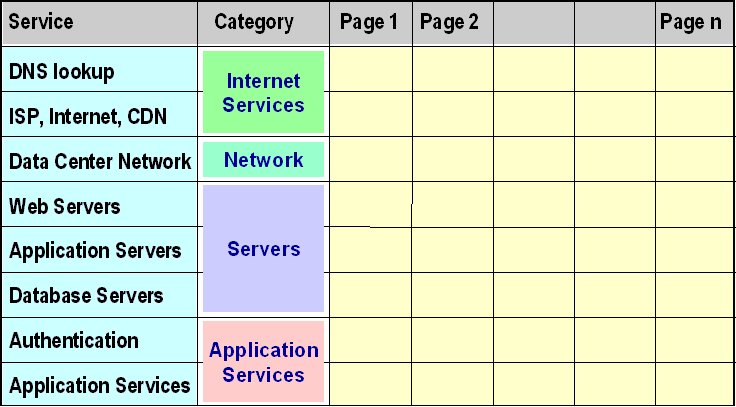
A reference model is an abstract framework for understanding significant relationships among the entities of some environment.In my two previous posts, I presented reference models for Web application availability and response time. These models enumerate the major components that determine the performance of any e-business application. This emphasis on identifying the contributing factors reveals another essential characteristic of all reference models -- the need for a model to be complete. Reference models for Web applications will be of limited use unless they offer a way to identify all the components the affect the availability or responsiveness of any Web-based application.
A reference model is based on a small number of unifying concepts and may be used as a basis for education and explaining standards to a non-specialist.
A reference model is not directly tied to any standards, technologies or other concrete implementation details, but it does seek to provide a common semantics that can be used unambiguously across and between different implementations.
Apart from their value as teaching tools, I see many potential uses for these reference models, no matter what aspect of SLM you need to focus on. By showing how the performance of the whole application is determined by the performance of its component parts, they can suggest:
- ways to determine the design goals and service level objectives (SLOs) for components
- the degree to which competing design ideas might improve performance
- frameworks for designing a performance monitoring program
- methods for predicting or summarizing overall availability or response times
- where to focus remediation efforts, identifying component(s) most in need of improvement
- ways to systematically evaluate and compare competing sites
- frameworks for comparing the likely impacts of different technology choices
For example, the CMG paper in which I first published the response-time reference model discusses examples of how e-commerce application response times can be improved in three ways: by reducing the overall number of components, by speeding up individual components, and by moving some components off the synchronous response time path.
Of course, a reference model will only take you so far. Because of their level, these models are designed only to break apart application availability and response time into their major components, not to reveal everything that goes on "under the covers." For that level of understanding, each component must be further dissected, as I did when discussing the components of Web response time in the CMG paper.But a reference model is usually a very good place to start from, no matter what your particular focus.
[Chris Loosley] 10/31/2005 10:00:00 PM
|
0 comments
![]()
![]()